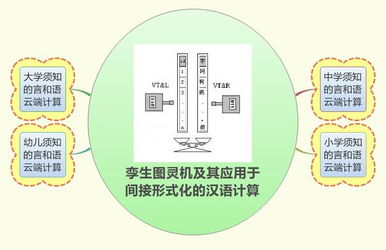
在當今信息爆炸的時代,如何高效、精準地處理海量的雙語知識信息,并對其進行深入的定量與定性分析,已成為跨學科研究與應用的關鍵課題。科學網博主鄒曉輝在其相關博文中,系統闡述了計算機輔助技術在雙語知識信息數據處理領域的應用前景、核心方法及服務模式,為我們理解這一前沿交叉領域提供了富有洞見的視角。
鄒曉輝強調了“計算機輔助”的核心地位。傳統的語言與知識處理高度依賴專家經驗,耗時費力且難以規模化。而現代計算技術,特別是自然語言處理、機器學習與大數據分析方法的引入,使得對多語言、多模態知識信息進行自動化或半自動化的采集、清洗、標注、對齊與整合成為可能。這不僅極大地提升了處理效率,也為發現隱藏在海量數據中的模式與關聯奠定了基礎。
博文深入探討了“雙語知識信息數據處理”的特殊性與挑戰。雙語處理并非兩種語言的簡單疊加,它涉及深層的語言對比、知識映射與文化語境轉換。鄒曉輝指出,有效的雙語數據處理服務,需要構建或利用高質量的雙語語料庫、知識圖譜(如跨語言知識圖譜)以及術語庫,并設計智能算法來實現概念、實體、關系在不同語言間的準確對齊與語義一致性保持。這對于機器翻譯、跨語言信息檢索、全球化知識服務等應用至關重要。
第三,關于“語言和知識的定量及定性分析”,鄒曉輝提出了一個整合框架。定量分析側重于利用統計學、計量語言學等方法,對語言現象(如詞頻、句法復雜度、語義相似度)和知識結構(如概念網絡密度、知識演化趨勢)進行量化測量與建模,以揭示其客觀規律與宏觀趨勢。定性分析則側重于結合領域專家知識,對定量結果進行解釋、評估與深化,理解數據背后的認知邏輯、文化內涵與應用場景。二者相輔相成,計算機輔助工具為兩者的結合提供了強大的技術支持,使得分析既能“見森林”(宏觀定量),又能“見樹木”(微觀定性)。
鄒曉輝的博文也指向了“數據處理服務”的實踐層面。這意味著將上述理論、方法與技術封裝成可對外提供的專業化服務或解決方案。這可能包括:為科研機構提供定制化的雙語文獻分析與知識發現服務;為企業(特別是跨國企業)構建多語言知識管理系統;或為教育機構開發智能化的雙語學習與評估工具。成功的服務需要融合語言學、計算機科學、特定領域知識以及對用戶需求的深刻理解。
鄒曉輝在科學網的博文勾勒出了一個以計算機技術為驅動,深度融合語言學、知識工程與數據分析的跨學科領域。它不僅是學術研究的熱點,更是推動全球化背景下知識高效流通、跨文化理解與智能化應用的重要基礎設施。隨著人工智能技術的持續進步,計算機輔助的雙語知識信息數據處理與分析服務,將在科學研究、商業決策、文化傳播等諸多領域發揮越來越不可或缺的作用。