隨著數(shù)據(jù)規(guī)模的爆炸式增長(zhǎng)和業(yè)務(wù)對(duì)實(shí)時(shí)性要求的不斷提高,大數(shù)據(jù)處理架構(gòu)經(jīng)歷了顯著的演進(jìn)。從早期的批處理主導(dǎo),到后來(lái)的Lambda架構(gòu)試圖統(tǒng)一批流,再到以Kappa架構(gòu)為代表的流處理優(yōu)先,直至如今流批一體與實(shí)時(shí)數(shù)倉(cāng)成為主流趨勢(shì),這一演進(jìn)過(guò)程深刻反映了數(shù)據(jù)處理范式與業(yè)務(wù)需求之間的動(dòng)態(tài)平衡。
一、Lambda架構(gòu):批流結(jié)合的經(jīng)典范式
Lambda架構(gòu)由Nathan Marz提出,其核心思想是通過(guò)并行運(yùn)行批處理層和速度層(流處理層)來(lái)平衡延遲、容錯(cuò)和可擴(kuò)展性。批處理層(如使用Hadoop MapReduce或Apache Spark)負(fù)責(zé)處理全量數(shù)據(jù),提供高準(zhǔn)確性的“批視圖”;速度層(如使用Apache Storm或Flink)負(fù)責(zé)處理實(shí)時(shí)增量數(shù)據(jù),提供低延遲的“實(shí)時(shí)視圖”;最后通過(guò)服務(wù)層合并兩者結(jié)果對(duì)外提供查詢。Lambda架構(gòu)的優(yōu)勢(shì)在于其魯棒性——批處理層可以修正速度層因?qū)崟r(shí)計(jì)算可能產(chǎn)生的誤差。其明顯缺點(diǎn)是復(fù)雜度高,需要維護(hù)兩套獨(dú)立的代碼邏輯和計(jì)算管道,導(dǎo)致開(kāi)發(fā)、運(yùn)維成本巨大,且兩套系統(tǒng)的一致性保障頗具挑戰(zhàn)。
二、Kappa架構(gòu):流處理統(tǒng)一天下的簡(jiǎn)化嘗試
為應(yīng)對(duì)Lambda架構(gòu)的復(fù)雜性,Jay Kreps提出了Kappa架構(gòu)。其核心主張是:所有數(shù)據(jù)都視為流,無(wú)需獨(dú)立的批處理層。系統(tǒng)只需一個(gè)流處理層,通過(guò)一個(gè)可重放的消息日志(如Apache Kafka)來(lái)存儲(chǔ)所有輸入數(shù)據(jù)。當(dāng)需要全量重新計(jì)算或修復(fù)邏輯時(shí),只需從頭重新消費(fèi)消息日志即可。Kappa架構(gòu)極大地簡(jiǎn)化了系統(tǒng)設(shè)計(jì),一套代碼處理所有場(chǎng)景。Apache Flink、Apache Samza等流處理引擎的成熟,為Kappa架構(gòu)提供了強(qiáng)有力的支撐。但其挑戰(zhàn)在于,對(duì)消息日志的長(zhǎng)期存儲(chǔ)與回溯性能要求極高,并且對(duì)于某些復(fù)雜的、周期性的全量計(jì)算(如歷史數(shù)據(jù)關(guān)聯(lián)分析),純流處理模式的效率可能不及批處理。
三、流批一體(Unified Batch & Streaming):架構(gòu)演進(jìn)的新方向
流批一體并非一個(gè)具體的架構(gòu),而是一種設(shè)計(jì)理念和框架能力,旨在讓開(kāi)發(fā)者能用同一套API和語(yǔ)義同時(shí)處理無(wú)界流數(shù)據(jù)和有界批數(shù)據(jù)。其理想狀態(tài)是:開(kāi)發(fā)一次,既能作為流任務(wù)低延遲運(yùn)行,也能作為批任務(wù)高吞吐運(yùn)行。Apache Flink是這一理念的先驅(qū)和典范,它通過(guò)其底層引擎將批數(shù)據(jù)視為一種特殊的、有界的流,實(shí)現(xiàn)了真正的運(yùn)行時(shí)統(tǒng)一。Google提出的Dataflow編程模型(后由Apache Beam SDK實(shí)現(xiàn))則從更高階的API層面統(tǒng)一了批和流的概念,允許開(kāi)發(fā)者將處理邏輯抽象為PCollection(數(shù)據(jù)集合)和Transform(轉(zhuǎn)換),并可以在不同后端引擎(如Flink, Spark, Google Cloud Dataflow)上執(zhí)行。流批一體解決了Lambda和Kappa架構(gòu)的核心痛點(diǎn),降低了開(kāi)發(fā)和維護(hù)的復(fù)雜性,是當(dāng)前大數(shù)據(jù)處理領(lǐng)域的主流方向。
四、Dataflow模型:抽象化的數(shù)據(jù)處理理論
Dataflow模型由Google在論文《The Dataflow Model》中提出,它不是一個(gè)具體系統(tǒng),而是一個(gè)用于定義流批統(tǒng)一數(shù)據(jù)處理邏輯的理論模型。它核心解決了兩個(gè)問(wèn)題:
1. 數(shù)據(jù)何時(shí)被處理? 通過(guò)引入事件時(shí)間和處理時(shí)間的概念,以及窗口化(固定窗口、滑動(dòng)窗口、會(huì)話窗口等)機(jī)制來(lái)組織無(wú)界數(shù)據(jù)。
2. 處理結(jié)果何時(shí)產(chǎn)出? 通過(guò)引入觸發(fā)器和累積模式(拋棄、累積、累積并撤回)的概念,來(lái)精確控制計(jì)算結(jié)果在何時(shí)、以何種方式輸出。
這個(gè)模型為流批一體提供了堅(jiān)實(shí)的理論基礎(chǔ),使得開(kāi)發(fā)者能夠清晰地推理亂序、延遲數(shù)據(jù)下的計(jì)算結(jié)果準(zhǔn)確性。Apache Beam SDK是這一模型最直接的實(shí)現(xiàn)。
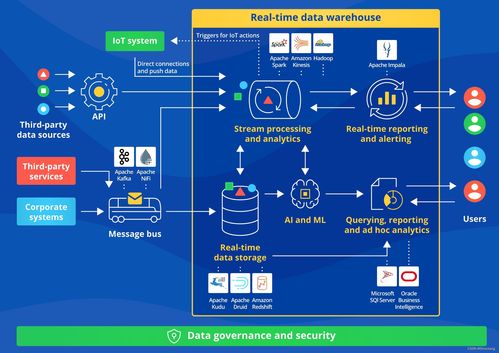
五、實(shí)時(shí)數(shù)倉(cāng):架構(gòu)演進(jìn)的目標(biāo)與承載
實(shí)時(shí)數(shù)倉(cāng)是現(xiàn)代數(shù)據(jù)架構(gòu)的集大成者,其目標(biāo)是建立一套能夠同時(shí)支持低延遲實(shí)時(shí)分析(亞秒到秒級(jí))和高效批量分析的數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng)。它不再是單一的組件,而是一個(gè)融合了多種架構(gòu)思想的完整解決方案:
- 數(shù)據(jù)接入層:通常基于Kafka等消息隊(duì)列,實(shí)現(xiàn)數(shù)據(jù)的實(shí)時(shí)采集與分發(fā)。
- 數(shù)據(jù)處理層:采用流批一體引擎(如Flink)或混合架構(gòu),對(duì)數(shù)據(jù)進(jìn)行實(shí)時(shí)ETL、清洗、聚合。
- 數(shù)據(jù)存儲(chǔ)層:采用分層設(shè)計(jì),如ODS(操作數(shù)據(jù)層)、DWD(明細(xì)層)、DWS(匯總層)、ADS(應(yīng)用層)。存儲(chǔ)選型多樣化,可能包括Kafka(實(shí)時(shí)管道)、OLAP數(shù)據(jù)庫(kù)(如ClickHouse、Doris、StarRocks用于即席查詢)、鍵值存儲(chǔ)(如HBase用于點(diǎn)查)以及數(shù)據(jù)湖(如Iceberg、Hudi用于全量歷史數(shù)據(jù))。
- 數(shù)據(jù)服務(wù)層:通過(guò)統(tǒng)一的查詢引擎或API網(wǎng)關(guān),對(duì)外提供一致的數(shù)據(jù)服務(wù)。
實(shí)時(shí)數(shù)倉(cāng)的本質(zhì)是讓數(shù)據(jù)流“實(shí)時(shí)”地流入并經(jīng)過(guò)處理,直接服務(wù)于數(shù)據(jù)應(yīng)用,打破了傳統(tǒng)T+1數(shù)倉(cāng)的滯后性。
六、數(shù)據(jù)處理服務(wù)(Data Processing as a Service):云原生的未來(lái)
隨著云計(jì)算的普及,大數(shù)據(jù)處理正在向服務(wù)化、托管化發(fā)展。各大云廠商(如AWS的EMR、Kinesis Data Analytics;阿里云的實(shí)時(shí)計(jì)算Flink版;Google Cloud Dataflow)提供了全托管的數(shù)據(jù)處理服務(wù)。用戶無(wú)需關(guān)心底層集群的部署、擴(kuò)縮容、監(jiān)控和運(yùn)維,只需專注于業(yè)務(wù)邏輯開(kāi)發(fā)。這種模式將復(fù)雜的架構(gòu)選擇和技術(shù)運(yùn)維負(fù)擔(dān)轉(zhuǎn)移給了云平臺(tái),讓企業(yè)能更敏捷地構(gòu)建實(shí)時(shí)數(shù)據(jù)能力,進(jìn)一步降低了大數(shù)據(jù)技術(shù)的應(yīng)用門檻。基于云原生的Serverless數(shù)據(jù)處理服務(wù),結(jié)合流批一體與實(shí)時(shí)數(shù)倉(cāng)理念,將成為企業(yè)數(shù)據(jù)基礎(chǔ)設(shè)施的標(biāo)準(zhǔn)配置。
###
從Lambda到Kappa,再到流批一體與實(shí)時(shí)數(shù)倉(cāng),大數(shù)據(jù)處理架構(gòu)的演進(jìn)是一條從“分離”走向“統(tǒng)一”,從“復(fù)雜”走向“簡(jiǎn)潔”,從“技術(shù)驅(qū)動(dòng)”走向“業(yè)務(wù)價(jià)值驅(qū)動(dòng)”的清晰路徑。Dataflow模型為此提供了理論基石,而云原生的數(shù)據(jù)處理服務(wù)則讓這些先進(jìn)架構(gòu)能夠以更經(jīng)濟(jì)、高效的方式落地。對(duì)于架構(gòu)師和開(kāi)發(fā)者而言,理解這些架構(gòu)背后的權(quán)衡與思想,比單純追求最新技術(shù)更為重要。選擇何種架構(gòu)或組合,應(yīng)深度結(jié)合業(yè)務(wù)場(chǎng)景的數(shù)據(jù)特征、時(shí)效性要求、準(zhǔn)確性要求、團(tuán)隊(duì)技能和成本約束來(lái)綜合決定。